
Abstract
In medical reporting, the accuracy of radiological reports, whether generated by humans or machine learning algorithms, is critical. We tackle a new task in this paper: image-conditioned autocorrection of inaccuracies within these reports. Using the MIMIC-CXR dataset, we first intentionally introduce a diverse range of errors into reports. Subsequently, we propose a two-stage framework capable of pinpointing these errors and then making corrections, simulating an autocorrection process. This method aims to address the shortcomings of existing automated medical reporting systems, like factual errors and incorrect conclusions, enhancing report reliability in vital healthcare applications. Importantly, our approach could serve as a guardrail, ensuring the accuracy and trustworthiness of automated report generation.
MedAutoCorrect

- Extract the image, patch and token embeddings from the image and text enconders.
- Train a per token classification model that learns to identify errors in reports.
- Train an error correction module (autoregressive LLM) conditioned on patch embeddings that learns to correct the masked errors.
- At inference use the error detection module to identify errors that would guide the placement of masks for the error correction module.
Assessing Error correction impact
While an end-to-end language model conditioned on image embeddings might seem like the obvious approach for mapping incorrect medical reports to correct ones, we find that a modular approach to medical autocorrection offers significant advantages. This method provides greater control over the correction process in an interpretable manner, allowing for more precise and explainable corrections.
Key Improvements: The images below show that the framework succeeds in correcting error relating to orientation (using visual cues from anatomical landmarks to correct patient orientation descriptions (e.g., changing 'lateral radiographs' to 'frontal radiographs')) and those regarding anatomical reconciliation (resolving discrepancies between described views and observed landmarks).

Error Sensitivity thresholds: We introduce the concept of an error sensitivity threshold that accounts for linient or strigent error detection would be. To adjust the error detection module’s performance, we utilize an “error sensitivity threshold", allowing for adjustable sensitivity in error detection. A threshold set closer to 1.0 results in a stringent detection approach, identifying more potential errors, whereas a setting closer to 0.6 yields a more lenient detection module, reducing the likelihood of false positives
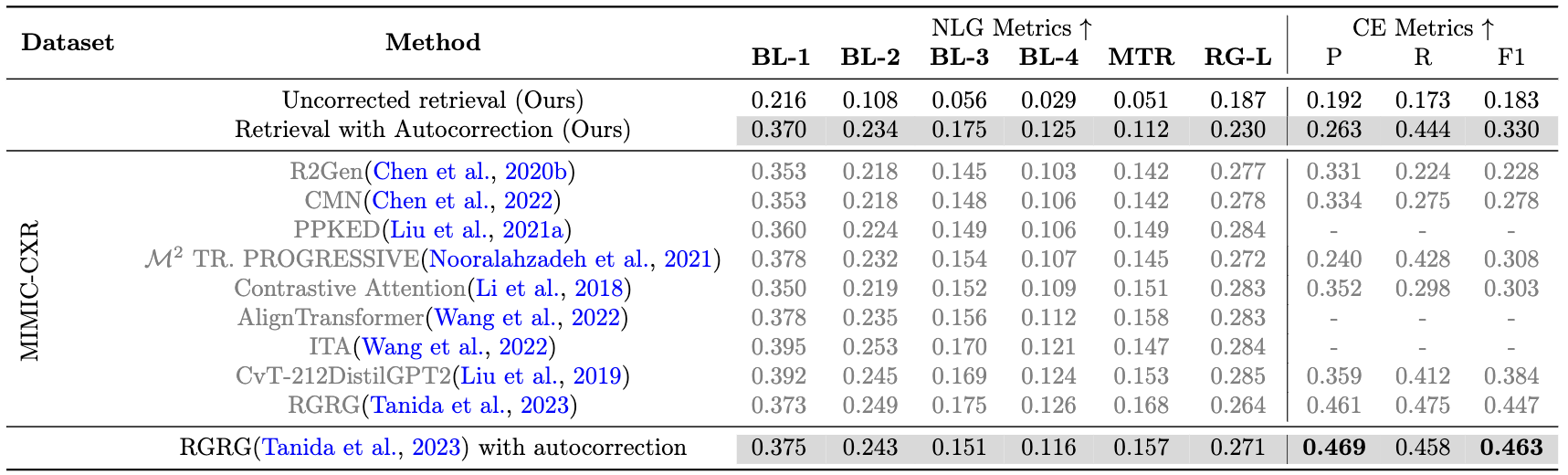
A guardrail for automatic report generation: We integrate the autocorrection system here, with a retrieval-based report generation model, and demonstrate signfificant improvements in accuracy and relevance of the generated medical reports. While the underlying report generation model wasn't optimized for state-of-the-art performance, the addition of autocorrection notably enhanced its output. A case study shown below shows this improvement.

Challenges in context-aware autocorrection of radiology reports: Sometimes, the autocorrection system, when applied to reports from retrieval-based generation models, faces a significant challenge. While the retrieval model can accurately fetch relevant reports, these often contain extraneous information not pertinent to the current diagnosis (highlighted in yellow). The autocorrection system struggles to identify and remove these non-essential segments that deviate from the ground truth. This limitation underscores the need for enhanced discernment capabilities to differentiate between essential and non-essential information in clinical contexts. Despite this challenge with extraneous content, the system continues to perform standard autocorrections on other aspects of the reports.

BibTeX
@misc{medautocorrect2024,
title={MedAutoCorrect: Image-conditioned autocorrection in medical reporting},
author={Arnold Caleb Asiimwe and Dídac Surís and Pranav Rajpurkar and Carl Vondrick}
year={2024},
eprint={},
archivePrefix={},
primaryClass={}
}